News
EgoVLPv2 has been released! Its new architecture demonstrates stronger performance and higher efficiency, outperforming EgoVLP across several benchmarks.
TL;DR
We pioneer Egocentric Video-Language Pretraining from pretraining dataset, model and development benchmark; the resulted pretrained model exhibits strong performance on five downstream tasks across three egocentric datasets.
EgoVLP Framework
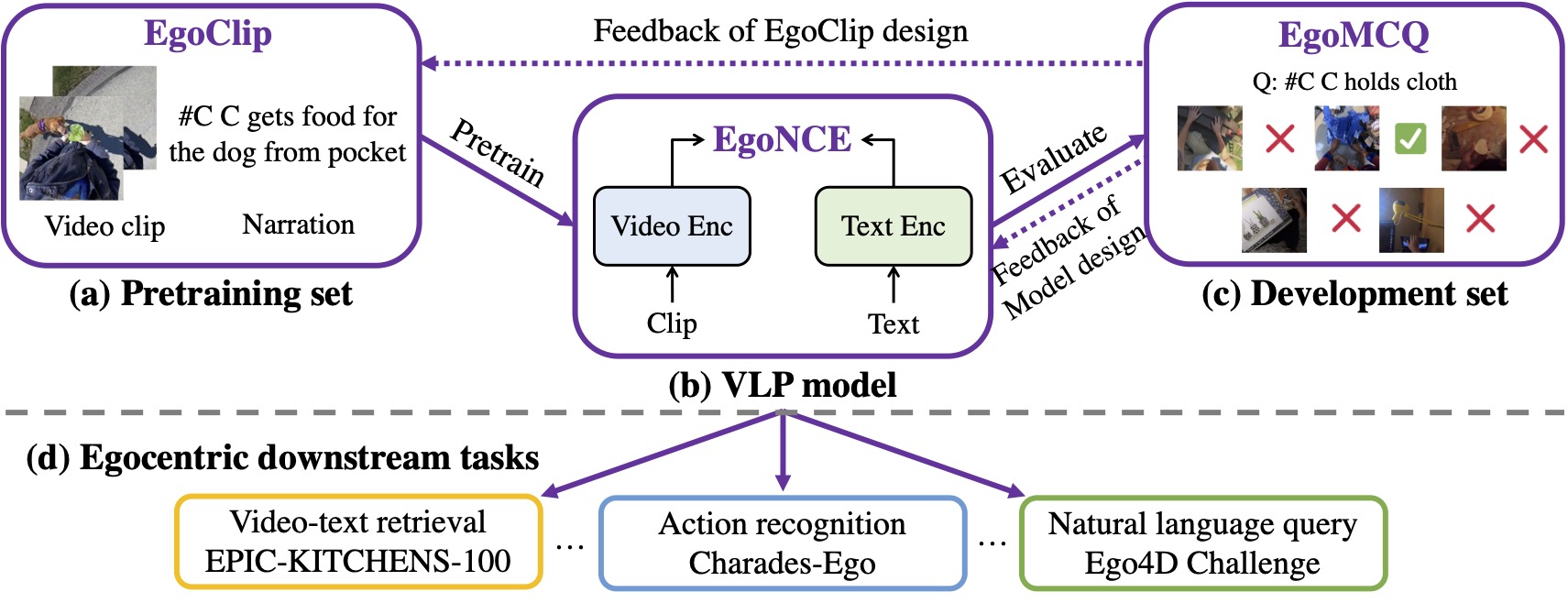
Our EgoVLP includes: (a) pretraining set EgoClip; (b) VLP model; and (c) development set EgoMCQ. We use EgoClip to pretrain a VLP model with EgoNCE loss and then evaluate on EgoMCQ. According to the feedback, we iteratively refine our designs of (a) and (b). We then transfer the pretrained model to downstream tasks relevant to the egocentric domain.
Abstract
Video-Language Pretraining (VLP), aiming to learn transferable representation to advance a wide range of video-text downstream tasks, has recently received increasing attention. Dominant works that achieve strong performance rely on large-scale, 3rd-person video-text datasets, such as HowTo100M. In this work, we exploit the recently released Ego4D dataset to pioneer Egocentric VLP along three directions. (i) We create EgoClip, a 1st-person video-text pretraining dataset comprising 3.8M clip-text pairs well-chosen from Ego4D, covering a large variety of human daily activities. (ii) We propose a novel pretraining objective, dubbed as EgoNCE, which adapts video-text contrastive learning to egocentric domain by mining egocentric-aware positive and negative samples. (iii) We introduce EgoMCQ, a development benchmark that is close to EgoClip and hence can support effective validation and fast exploration of our design decisions regarding EgoClip and EgoNCE. Furthermore, we demonstrate strong performance on five egocentric downstream tasks across three datasets: video-text retrieval on EPIC-KITCHENS-100; action recognition on Charades-Ego; and natural language query, moment query, and object state change classification on Ego4D challenge benchmarks.
BibTeX
@article{kevin2022egovlp,
title={Egocentric Video-Language Pretraining},
author={Lin, Kevin Qinghong and Wang, Alex Jinpeng and Soldan, Mattia and Wray, Michael and Yan, Rui and Xu, Eric Zhongcong and Gao, Difei and Tu, Rongcheng and Zhao, Wenzhe and Kong, Weijie and others},
journal={arXiv preprint arXiv:2206.01670},
year={2022}
}