Kevin Qinghong LinPh.D. Student
Show Lab
|
 Photo taken on Rottnest Island. |




Biography
Hi, I am a Ph.D. student in Show Lab @ NUS, working with Prof. Mike
Shou.

My research focuses on Video Understanding and Language Models, aiming to develop assistants to streamline human tasks.
News
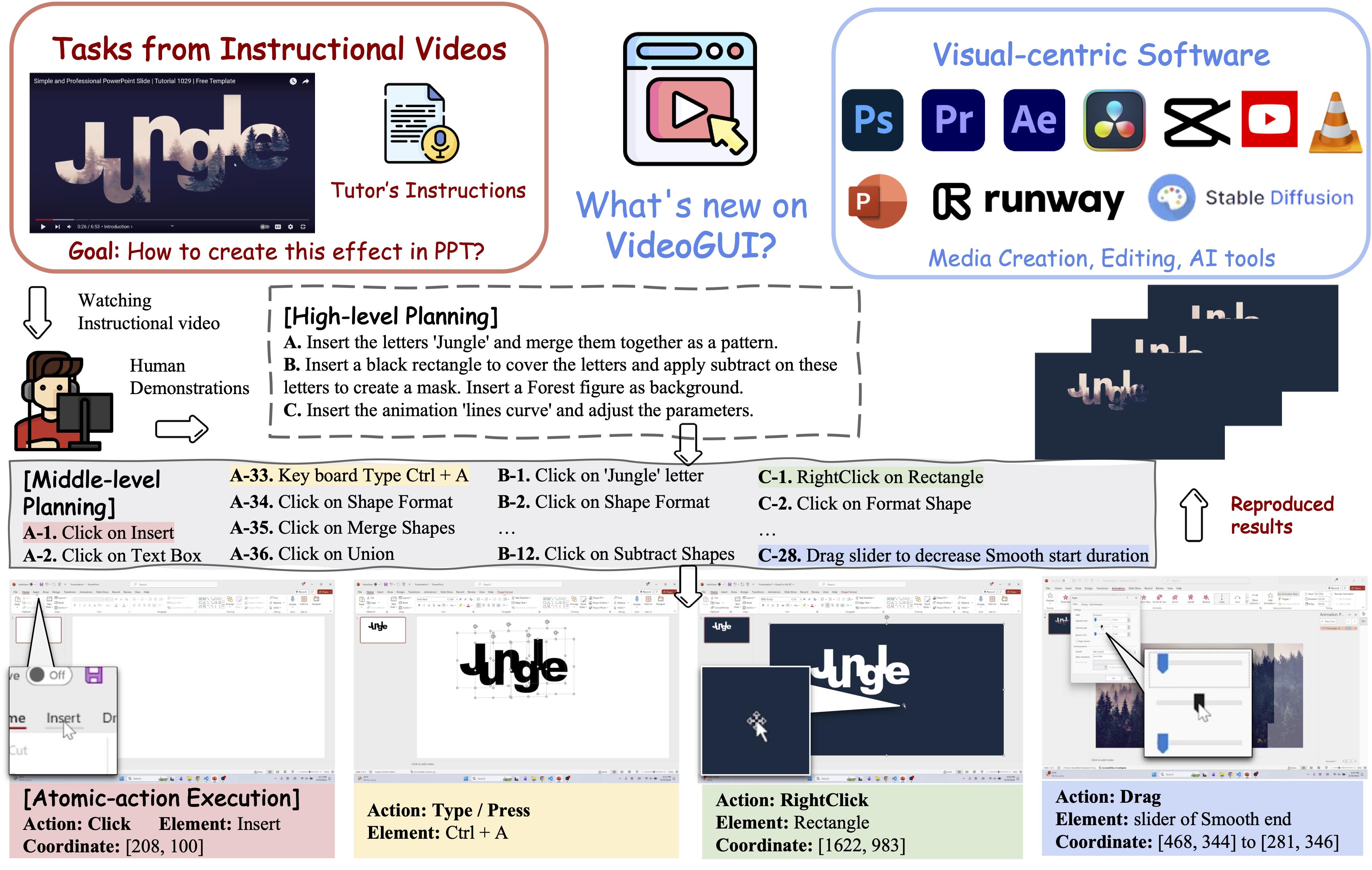
- 2024 Sept: VideoGUI (D&B Spotlight), VideoLLM-MoD got accepted by NeurIPS 2024.
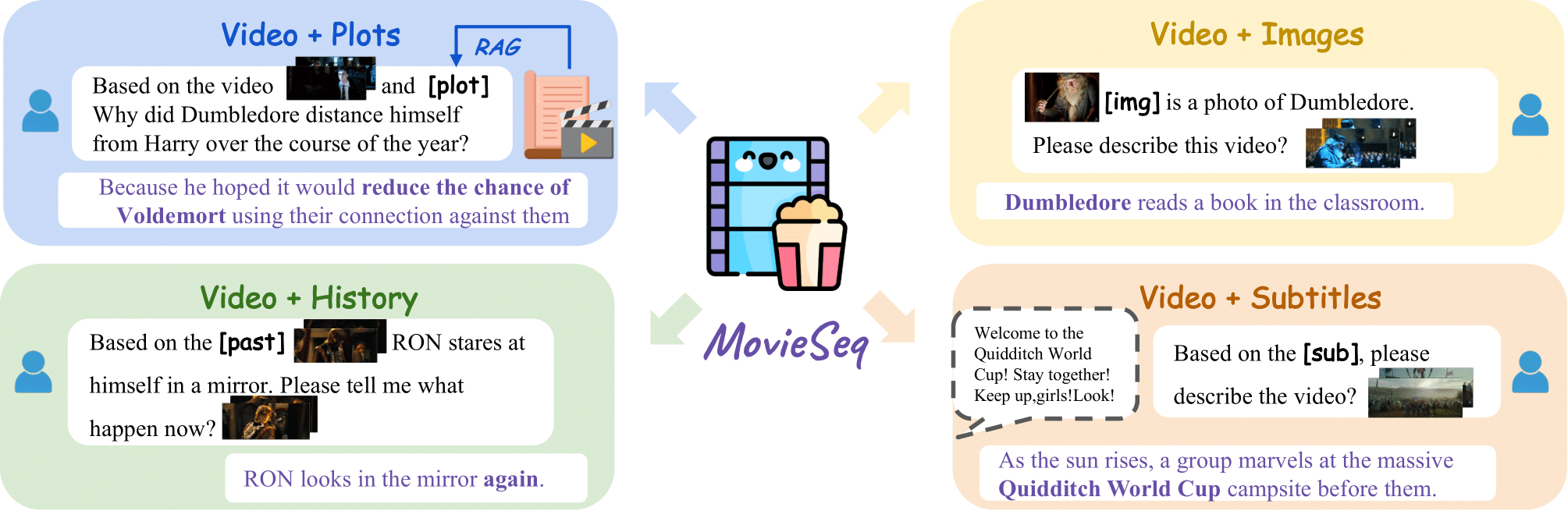
- 2024 July: MovieSeq got accepted by ECCV 2024.
- 2024 Jun: EgoVLP received Egocentric Vision (EgoVis) Distinguished Paper Award.
- 2024 May: Recognized as CVPR 2024 Outstanding Reviewers.
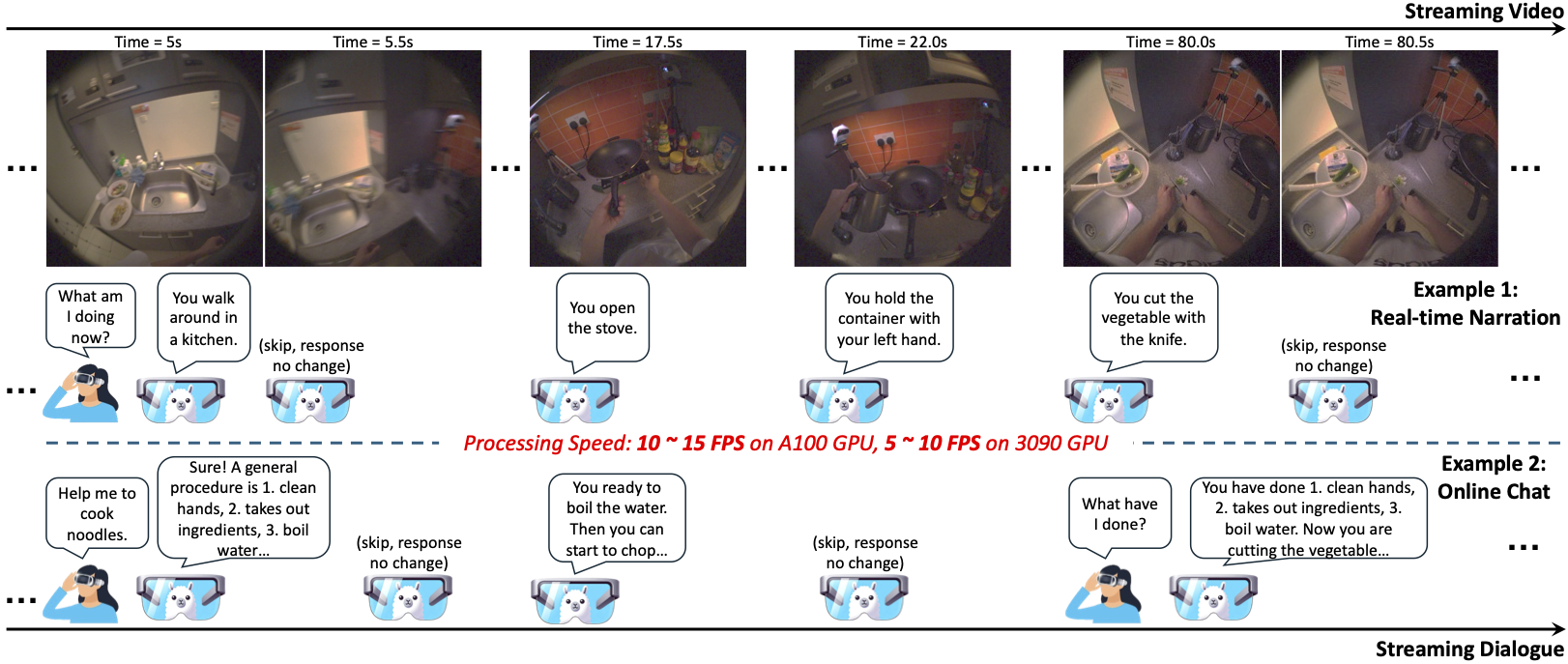
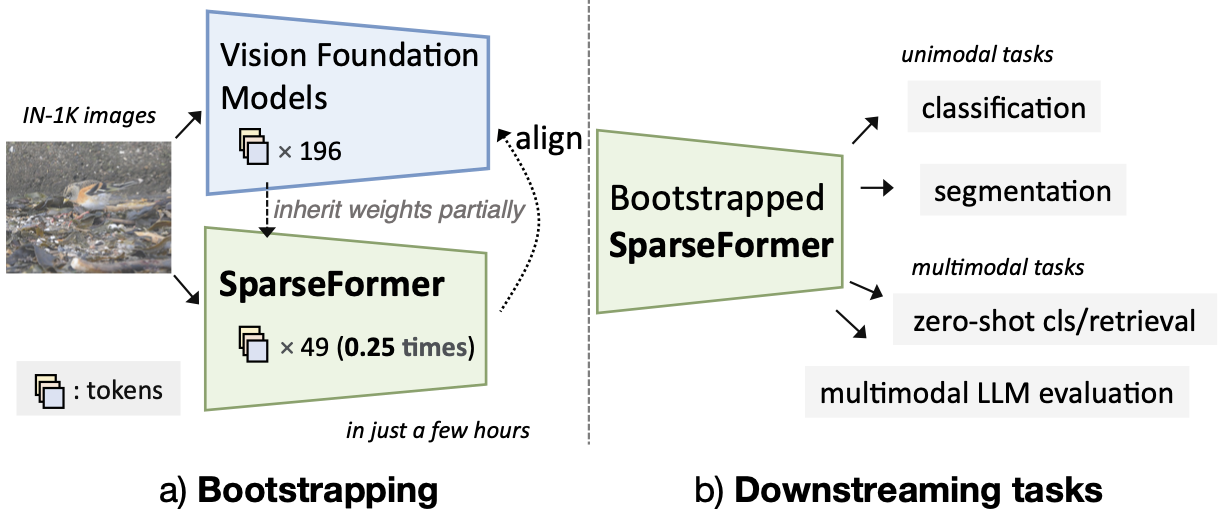
- 2024 Feb: VideoLLM-online, SparseFormer got accepted by CVPR 2024.
- 2023 Sept: VisorGPT got accepted by NeurIPS 2023.
- 2023 Aug: EgoVLP received PREMIA Best Student Paper Award (Gold award).
- 2023 July: UniVTG, EgoVLPv2, TL;DR got accepted by ICCV 2023.
- 2023 Mar: All-in-one, Afformer got accepted by CVPR 2023.
- 2022 Sept: EgoVLP got accepted by NeurIPS 2022 as Spotlight.
- 2022 Aug: Joined Show Lab @ NUS to start my Ph.D. journey!
- 2022 Jun: EgoVLP won Double Champions of Joint 1st Ego4D and 10th EPIC Workshop, CVPR 2022. [News]
Publications

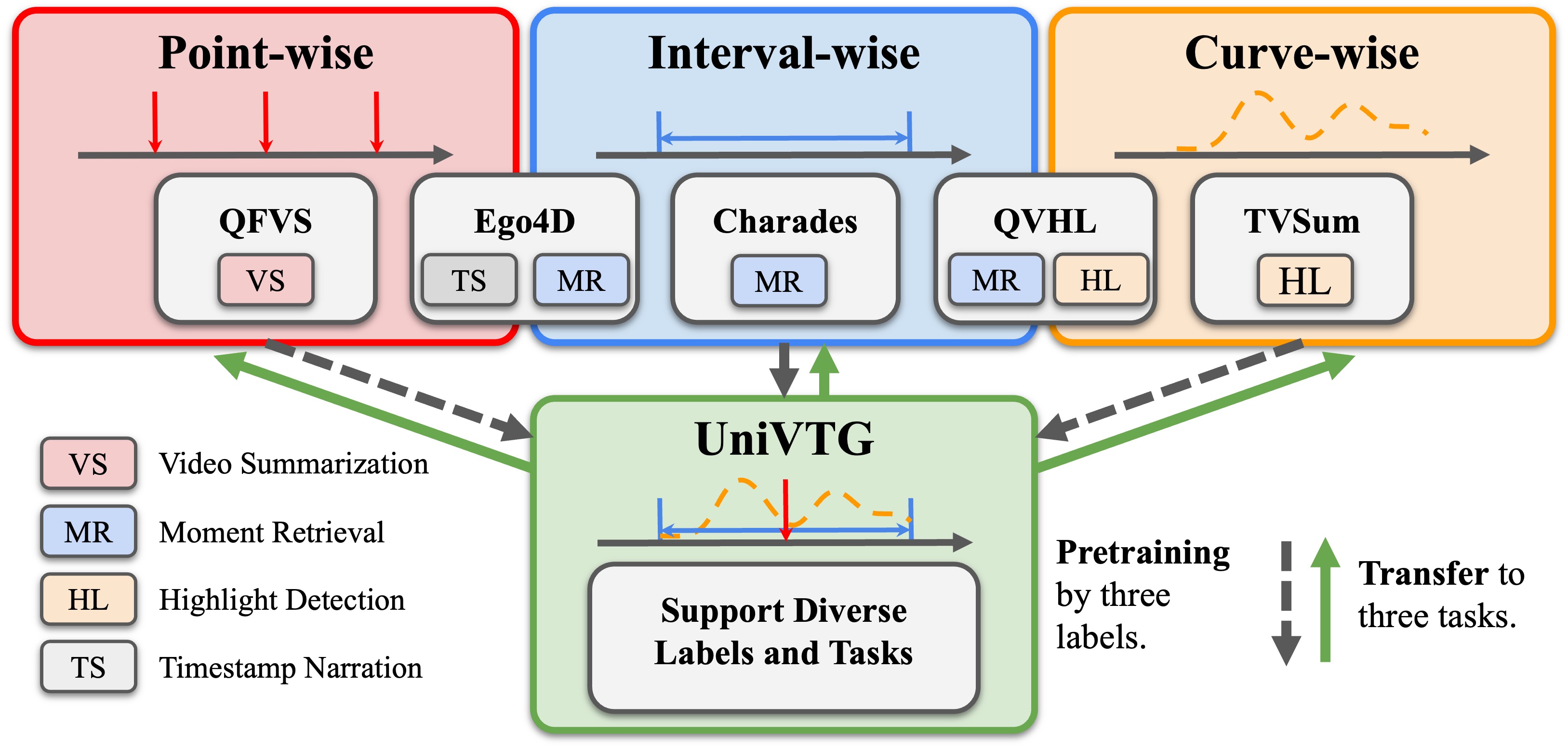
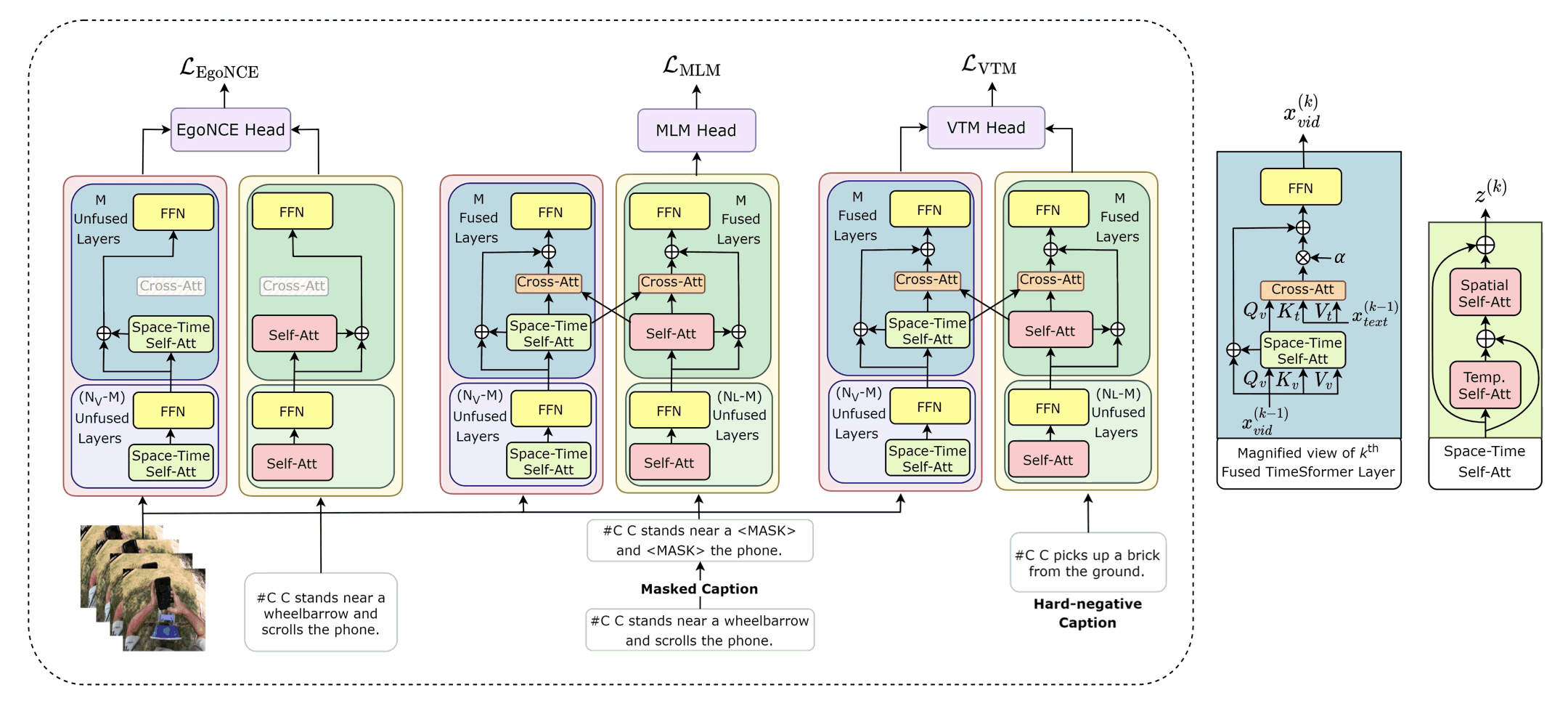
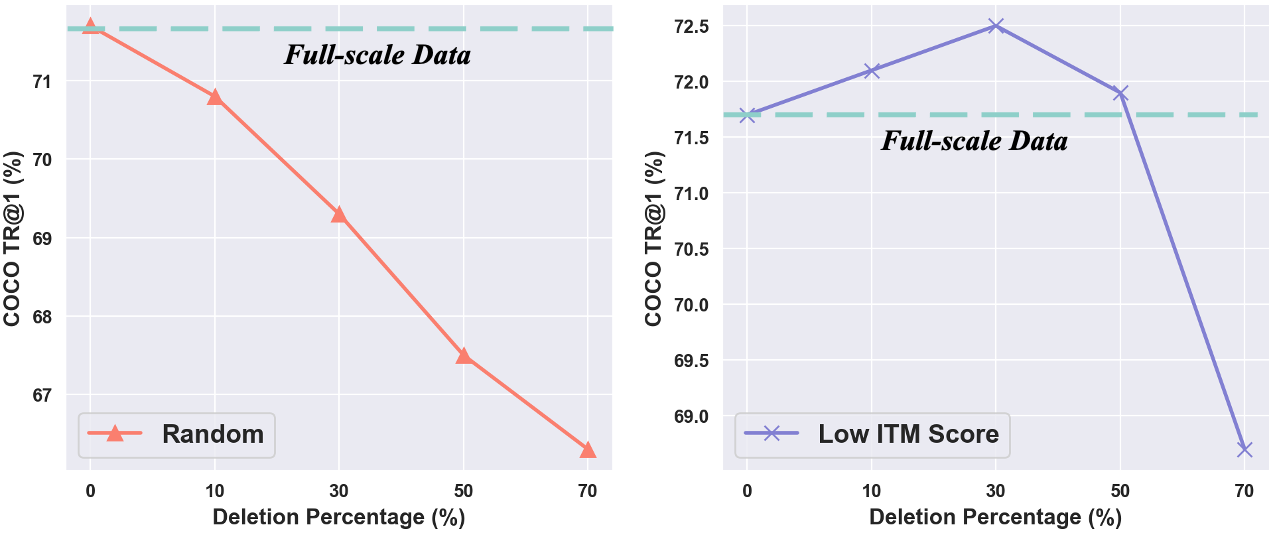
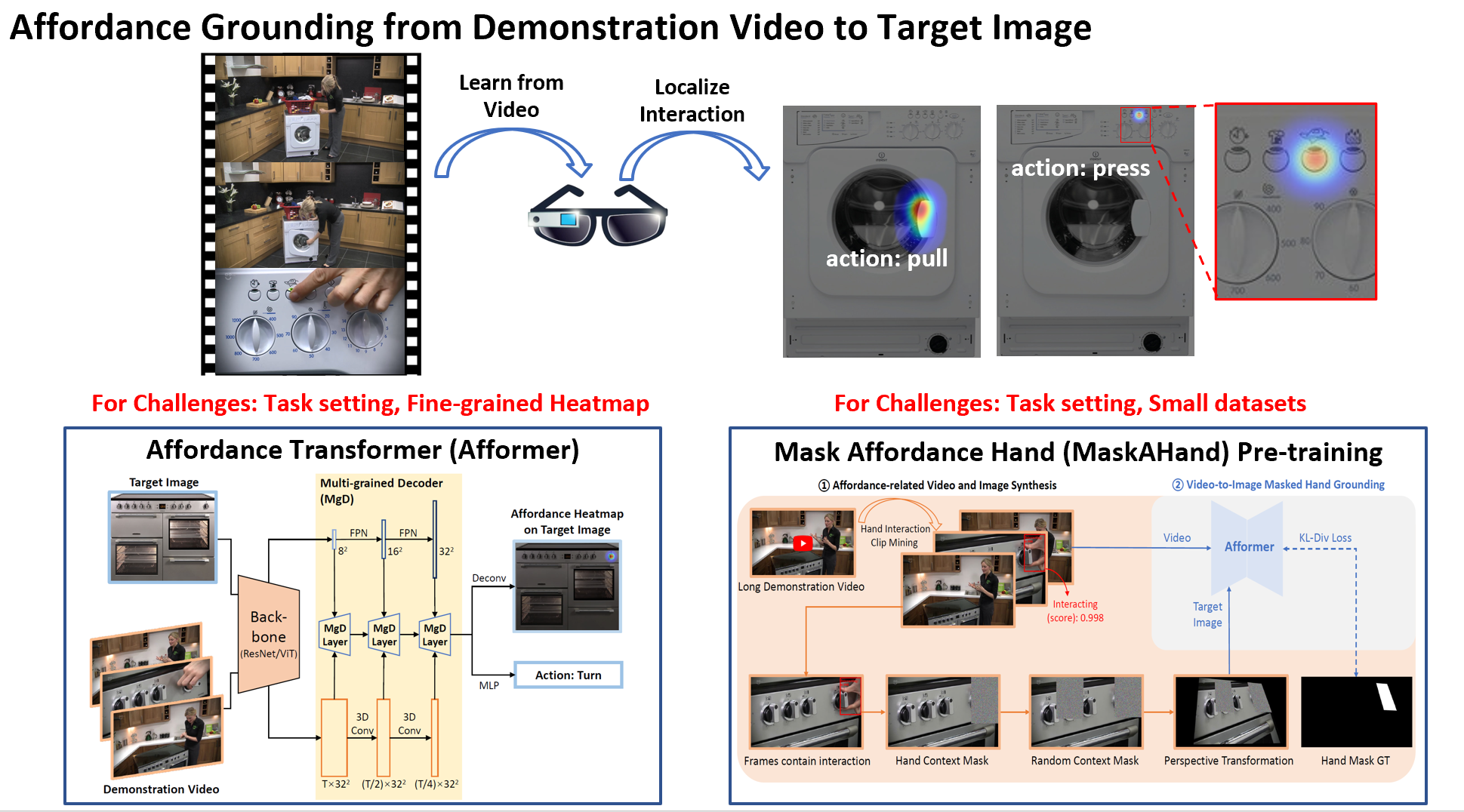
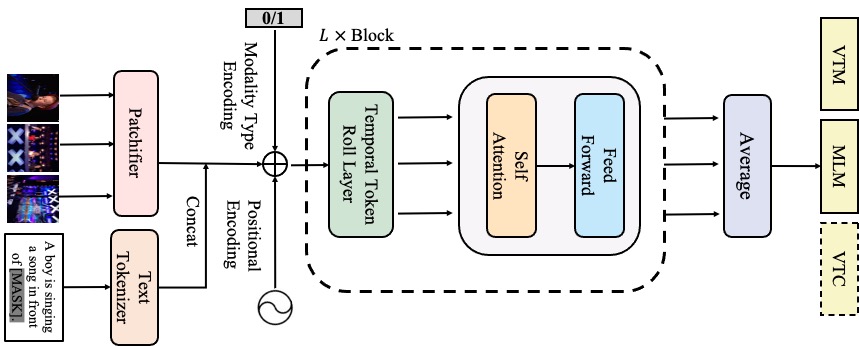
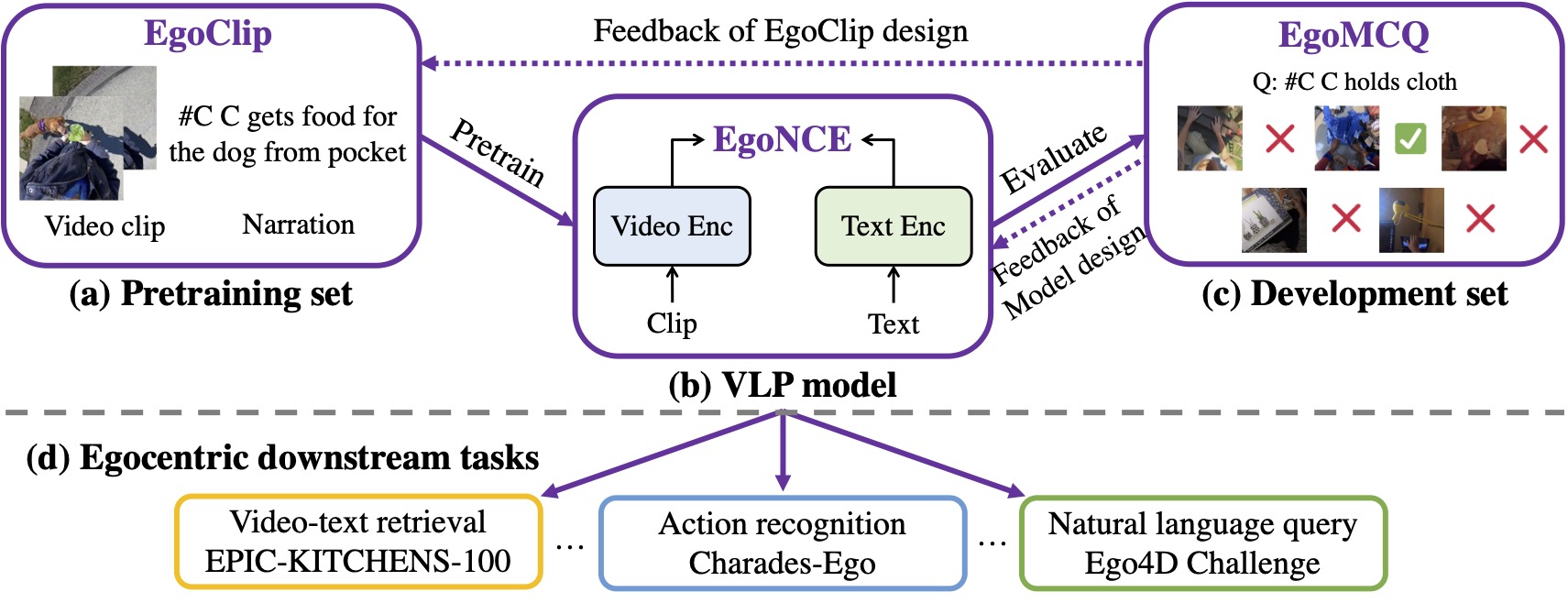
Projects
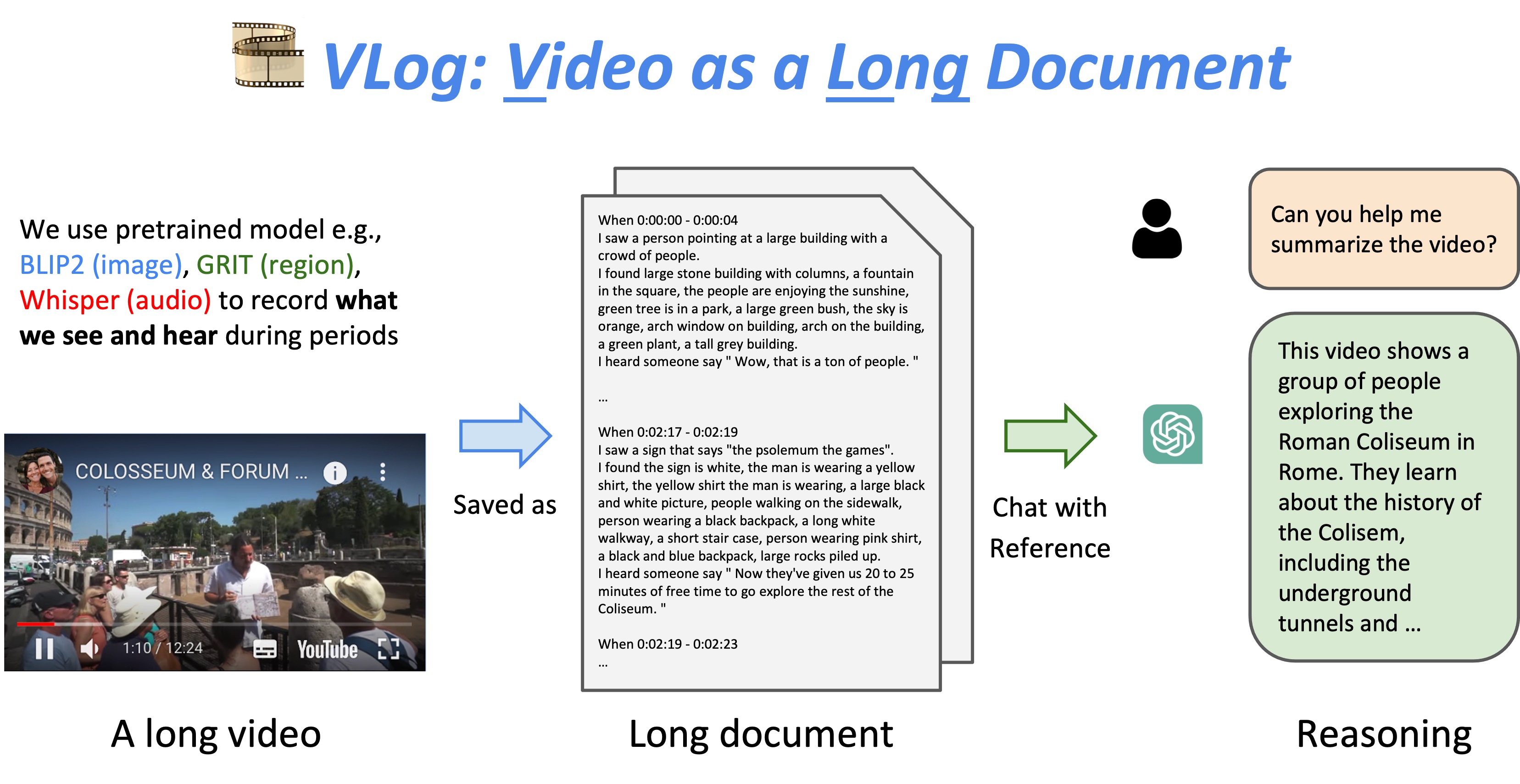
|
VLog: Video as a Long Document
[demo]
[code]
[twitter]
|
Honors
-
Egocentric Vision (EgoVis) Distinguished Paper Award2024
-
CVPR Outstanding Reviewers2024
-
PREMIA Best Student Paper Awards, Gold Award2023
-
Show Lab Annual Award2022
-
NeurIPS Scholar Award2022
-
Tencent Rhino-Bird Research Scholarship, Second Prize2022
-
1st Place on Ego4D - Object State Change Classification Challenge, CVPR2022
-
1st Place on EPIC-Kitchens - Multi-Instance Retrieval
Challenge, CVPR2022
-
China National Scholarship2018, 2021
Service
-
Journal Reviewer: TPAMI, IJCV, TNNLS, TMM, Neurocomputing, Pattern Recognition, etc.
-
Co-organizer of The AI Talks.
Conference Reviewer: CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, ACL, EMNLP, ACM MM, KDD, AAAI, IJCAI, ICME, ICASSP.
© Kevin